FUN편log 프로젝트 3주차 회고
목차
- 시작하며
- 1회차 멘토링
- 깃플로우 적용
- 배포 이슈
- 2회차 멘토링
- 마치며
시작하며
벌써 3주차가 끝나가고 있다는 사실이 믿기지 않는다.. 옛날부터 느낀 거지만 프로젝트를 수행하고 있는 동안에는 시간이 항상 생각보다 빨리 지나가는 것 같다.
3주차부터 마지막 주차까지는 멘토링에서 하는 것들이 진행 현황 및 이슈 체크로 정해져 있다.
그래도 멘토링에 들어가기 30분 정도 전에 진행 상황과 현재까지 발생한 이슈들에 대해 텍스트 편집기에 한번 적어보고 멘토링을 받아서인지 막히는 부분이나 현재 수행 중인 작업을 완료하면 어떤 것들을 할지에 대한 것들이 생각보다 머릿속에 잘 정리되는 느낌이 들었다.
1회차 멘토링
제일 처음에는 진행 상황 및 이슈 체크를 하는 시간을 가졌다.
백엔드의 경우 배포와 관련한 이슈가 있어서 그에 대해 이야기했다.
- 프로젝트를 완전히 배포하기 전에 배포가 제대로 되었을 때를 체크하기 위해서 소스에 임시로 "/hello"요청을 했을 경우에 "hello"를 리턴해주는 RestController를 만들어 두었다.
- 멘토님이 공유해주신 배포할 때 참고할 자료를 토대로 차근차근 단계를 밟아가며 배포하기 버튼을 눌렀다.
- 배포하기 버튼을 누르기 전까지 크게 두 가지의 문제 상황이 있었는데, 나는 하나씩 변경해가며 배포하기 버튼을 눌렀다.
- build.gradle 파일에 작성된 Gradle저장소 위치에 문제가 있었고, Gradle에 대한 지식이 부족해 구글링을 통해 이를 해결했다.
- 루트에 Procfile 파일을 생성하지 않았다. (나중에 알게 되었음)
- 배포 시도를 약 50회 정도 실시했다.
- Qoddi의 자동 방어 시스템에 의해 계정이 막혔다.
사실 2주차 멘토링에서 멘토님이 배포를 제일 먼저 할 거라고 말씀해주셨고, 우리가 사용할 배포 서비스인 Qoddi를 사용하는 방법이 담긴 블로그 링크도 전달받아서 이대로 하면 되겠다는 생각을 가지고 평소에 테스트하듯이 배포를 시도했는데 그게 문제가 되었다.
이런 이슈를 해결하기 위해 일단 개인적으로 Qoddi에 메일로 문의를 넣었지만 지금 바로 해제시킬 수는 없다는 답변을 받았다.
이번 프로젝트에서는 거의 무조건 Qoddi를 사용하기로 했기도 했고, 원래 사용하기로 했던 Heroku는 유료화되었기 때문에 청천벽력 같은 이야기였다.
멘토님께서는 일단 시간이 촉박한 건 아니기 때문에 문의는 계속적으로 해보면서 프로젝트 먼저 진행하자고 하셨고 이슈 체크 시간을 종료했다.
이후에 저번 주에 말씀했던 Git, Github에 대한 간단 요약 강의를 듣게 되었다.
이번 멘토링에서는 현업에서 Git과 Github를 사용할 때 유용한 꿀팁들에 대한 이야기를 들었는데, 확실히 멘토님들이 현업에서 사용하면서 직면했던 문제들에 대해 많이 고민하셨다는 게 느껴져서 좋았다.
Git과 Github에 대한 요약정리가 끝나고 이어서 깃플로우(GitFlow)에 대한 설명을 들었다.
확실히 이전까지의 나는 터미널 창에서 단순히 Push, Pull, Clone만 사용해서 main브랜치에 접근했었다.
물론 깃플로우에 대해 들어보지 않은 것은 아니었지만 깃플로우에 대해 말로 직접 설명을 들으니 이해도 더 잘되는 느낌이었고, 뭔가 사용해볼 수 있을 것 같은 느낌이 들었다.
깃플로우 적용
멘토님께 들었던 깃플로우 강의에 대한 기억 및 필기 자료를 더듬어가며 여러 개의 브랜치를 만들었다.

develop 브랜치와 각각의 기능 개발을 진행할 때 사용할 feature 브랜치를 여러 개 만들었고, 아마 이전에 작성한 칸반 보드의 아이템 하나당 거의 하나의 브랜치를 만들게 될 것이라고 한다.
로컬 브랜치와 동일한 이름으로 원격에도 아래처럼 브랜치를 만들었다.

나름 브랜치를 여러 개 만들고 보니 뭔가 진행하는 느낌이 들어서 좋았다.
원래는 이렇게 브랜치를 만들기 전에 배포 먼저 연습한 후에 개발을 진행하기로 했지만, 배포 관련 이슈가 있었기 때문에 멘토님께서 일단 API부터 만들어보자고 하셨다.
그래서 feature브랜치로 옮겨가서 개발을 진행하고 push를 해야 하나 생각했는데, 그러지 않고 reviewer로 멘토님을 지정해서 pull request를 보내면 멘토님이 확인하시고 merge작업을 진행한다고 하셨다.
따라서 나는 멘토님 말씀대로 일단 Jpa Entity의 동적 로딩 방식을 검토 후 eager -> lazy로 변경할 부분에 대해 변경 후 pull request를 생성했고, 멘토님께서 merge 해주셔서 develop 브랜치에 병합되는 과정을 수행했다.
뭔가 pull request를 보내고 리뷰어를 설정하는 등의 작업이 해보기 전까지는 좀 어렵고 멀게 느껴졌는데, 막상 해보니 그렇게 어렵지는 않아서 괜찮았다.
배포 이슈
위에서 언급했던 배포 이슈때문에 3회 정도 Qoddi의 공식 메일로 문의를 넣었다.
그런데 처음엔 당장 풀어줄 수 없다는 메일을 비교적 빨리 회신해줬던 것 같은데, 그럼 언제쯤 풀어줄 수 있는지에 대한 문의 메일에는 답변이 오랫동안 오지 않았다.

다른 계정으로 가입하려고 해도 되질 않았고, 답이 오지 않은 채로 시간이 지날수록 뭔가 점점 초조해갔다.
아마도 Qoddi 공식 사이트를 보니 현지와 한국의 시차가 존재하기 때문에 내가 메일을 보낸다고 해도 바로 답장을 주지 못하는 것은 이해하겠지만, 며칠이 지나도록 회신이 오지 않아서 더 불안했던 것 같다.
내가 마지막으로 시도했던 것은 Qoddi 공식 사이트에 있는 챗봇에 제발 도와달라는 메시지를 보내는 것이었다.
다행히도, 챗봇 담당자가 남아있었다.

나의 영어 실력은 미비했지만 창대한 파파고를 사용하여 원활한 의사소통을 할 수 있었다.
여담이지만, 사진에서 내가 보낸 메시지의 가장 아래에 있는 "I beg you"라는 문장이 제발요라는 뜻이라고 한다^^
담당자의 말로는 내 계정에서 배포 시도를 단 기간에 매우 많이 시도했기 때문에 자동 방어 시스템에 의해 계정이 비활성화된 것이라고 한다.
아마도 하나씩 바꿔가며 계속 배포를 시도한 것이 화근이 된 듯하다...
어쨌든 어찌어찌 나에게 악의가 없었고, 앞으로 조심해서 쓰겠다는 내용을 전함으로써 계정을 다시 활성화할 수 있었다!!
2회차 멘토링
이번 멘토링에서는 시간 절약을 위해 백엔드와 프론트엔드 두 팀으로 나누어 멘토링을 진행했다.
이전에 배포 관련 이슈가 해결되기 전에 편의점 요약 정보를 한 건 혹은 여러 건 요청했을 때 응답하기 위한 로직을 작성하고 있었기 때문에 이 건만 마치고 배포를 해보기로 했었다.
내가 제일 처음에 작성한 편의점 요약 정보에 대한 로직은 아래와 같다.
get 요청을 받으면 service에서 해당 편의점에 대한 리뷰, 키워드를 모두 가져와서 [리뷰 개수], [별점 평균], [대표 키워드 3개]를 구한 후에 객체로 묶어서 리턴해준다. -> 메시지 컨버터에 의해 json으로 변환되어 리턴된다.
** 여기서 키워드는 편의점을 대표할만한 말을 의미한다. 예를 들어 "분위기가 좋아요", "접근성이 좋아요" 등이 될 수 있다.
로직을 작성하고 포스트맨으로 테스트까지 해서 성공했기 때문에 push 하고 pull request를 생성했는데, 멘토님께서 코멘트에 이렇게 하면 조회할 때 만약 리뷰가 많은 편의점의 경우 부하가 많이 생길 것 같다는 피드백을 해주셨다.
나도 어느 정도 공감했다. 왜냐면 나도 로직을 작성하면서 성능이 버텨주지 못하면 어떡하지라는 약간 불안한 생각을 갖고 있었기 때문이다.
다른 부분은 괜찮았는데 대표 키워드를 구하는 부분에서 키워드 테이블에서 편의점 아이디가 같은 것들을 List로 뽑아온 후에 그중 가장 많은 수의 키워드를 뽑아서 정렬해야 하고 이 과정에서 댓글이 많이 달린 편의점의 경우에 부하가 발생할 수 있을 것 같았다.
개인적으로는 서비스를 이용하는데 정보를 조회하는 기능에서 부하가 발생하면 아무리 서비스가 좋아도 잘 안 쓰게 될 것 같았다.
멘토님께서 멘토링이 시작되기 전에 편의점 요약 정보에 대한 테이블을 따로 만들고 리뷰 생성(post) 요청을 수행하면서 해당 값을 업데이트하고, 조회할 때는 요약 정보가 저장된 테이블에서 정보 한 건만 꺼내서 리턴해주는 식으로 해보자고 말씀하셨다.
물론 사용자가 많아지면 문제가 될 수는 있지만 어쨌든 그건 사용자가 많기 때문에 발생하는 문제이고, 조회에서 부하가 발생하는 것보단 업데이트와 부하를 나눠가지는 게 훨씬 맞는 것 같았다.
그런데 여기서 편의점 요약 정보 테이블을 만드는 건 나도 동의하는 바이지만, '대표 키워드 3개에 대해 컬럼을 만들어야 할까?'라는 고민이 생겼다. 왜냐면 대표 키워드는 현재는 3개로 하기로 했지만, 변경될 가능성이 많다고 생각했기 때문이다.
그래서 멘토링이 시작되고 제일 처음 진행된 질의응답 시간에 위 내용에 대한 이야기를 했다.
멘토님께서는 이런 경우에는 일반적으로 각 테이블의 PK를 FK로 갖고 있는 중간 테이블을 만들어서 각 테이블의 매핑 정보 및 부가 정보를 저장한다고 하셨고, 뭔가 막힌 부분이 뚫리는 듯한 느낌이 들었다.
나는 멘토링을 진행하면서 이를 즉각적으로 erd에 적용시켰고, 일단 배포를 진행하기 전에 아래 사진처럼 Jpa Entity 구조 만들기와 편의점 요약 정보를 조회하는 로직만 만들어보기로 했다.
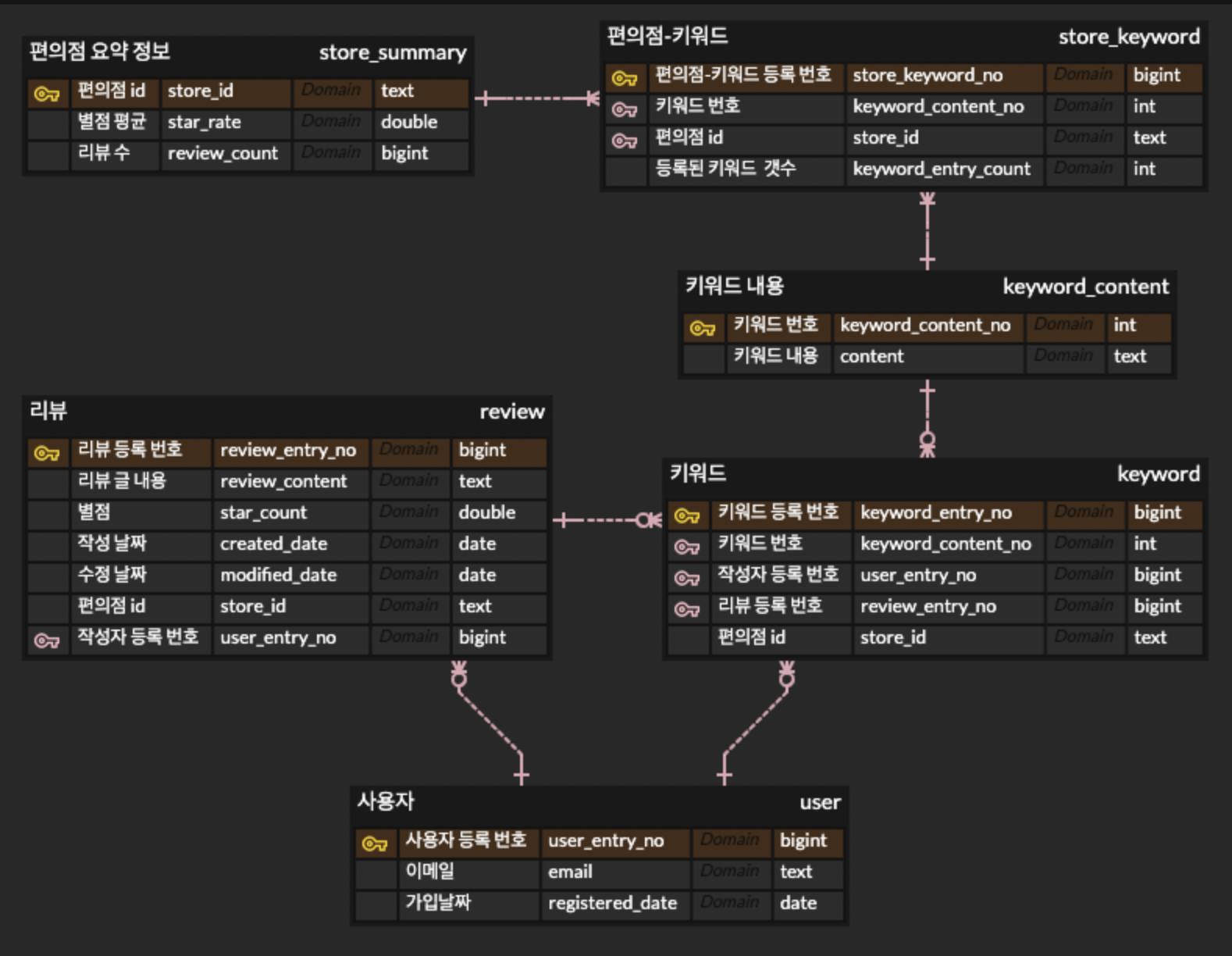
이 외에 멘토링 내용은 아래와 같다.
- 스프링 시큐리티에 대한 기본 설명
- 세션, 쿠키의 정의
- OAuth를 쓰는 이유
- JWT
- 필터
- 클래스별 로직 책임을 생각하자
- 컨트롤러에서는 Http 요청 전문을 받아올 수 있다.
- 핸들러 메소드에서 수용 가능한 파라미터 타입에 대해 공부하면 좋다
- 프론트엔드에서도 배포를 할 것이기 때문에 백엔드의 부하가 줄어들 것이다.
마치며
다음 주까지 해야 할 과제
- Jpa StoreSummary부분 만들어서 pull request
- 시큐리티 만들어서 cors 해오기 (일단 보류)
- 배포해보기(Qoddi)
뭔가 이번 주는 질의응답 시간과 시큐리티의 이해를 돕기 위한 강의, 깃 플로우에 대한 설명이 엄청 유용했던 것 같다.
감사합니다!!